Given as input a set of class-agnostic 2D masks with little consistency across views, we aim to learn a meaningful 3D object field that segments the different instances in the scene. The discovered objects can then be extracted and rendered independently.
Abstract
Radiance Fields have become a powerful tool for modeling 3D scenes from multiple images. However, they remain difficult to segment into semantically meaningful regions. Some methods work well using 2D semantic masks, but they generalize poorly to class-agnostic segmentations. More recent methods circumvent this issue by using contrastive learning to optimize a high-dimensional 3D feature field instead. However, recovering a segmentation then requires clustering and fine-tuning the associated hyperparameters. In contrast, we aim to identify the necessary changes in segmentation field methods to directly learn a segmentation field while being robust to inconsistent class-agnostic masks, successfully decomposing the scene into a set of objects of any class.
By introducing an additional spatial regularization term and restricting the field to a limited number of competing object slots against which masks are matched, a meaningful object representation emerges that best explains the 2D supervision. Our experiments demonstrate the ability of our method to generate 3D panoptic segmentations on complex scenes, and extract high-quality 3D assets from radiance fields that can then be used in virtual 3D environments.
Method
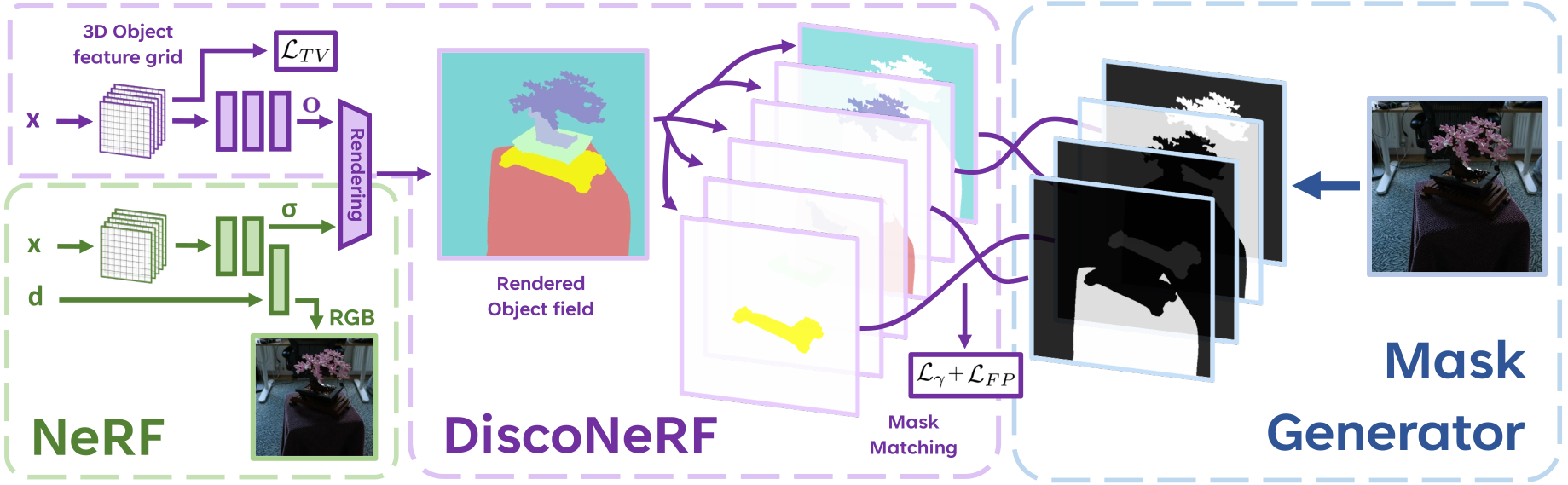
In this work, we propose DiscoNeRF, an approach to discover 3D objects in an open-world environment. DiscoNeRF segments 3D radiance fields without a preset number of classes or user-interaction while still producing sharp segmentations.
Our key insight is that we can efficiently constrain the training of an object field to produce a view-consistent 3D segmentation despite the noisiness of the supervisory signal.
In addition to the density and color that a standard radiance field predicts at each point in a volume, ours predicts a vector of probabilities of belonging to a particular object. These vectors are then used to render images whose pixels are the probabilities to belong to each class. Note that these object classes are not assigned a semantic meaning, they simply correspond to a channel in the probability vector. To enforce consistency across views between probability images and 2D segmentation masks, we introduce a robust loss function that generalizes the traditional Intersection over Union (IoU) measure to floating point values and relies on the Hungarian algorithm to establish correspondences between regions in the probability images and 2D masks in the segmentations. Minimizing this loss function using the appropriate regularization constraints yields the desired result.
Results
Since our method can segment 3D scenes into individual objects, the 3D reconstructions can be used in downstream applications. An object can be extracted by conditioning the rendering of the model to only render the associated slot.
In our experiments, we also compare both quantitatively and qualitatively with several state-of-the-art radiance field segmentation methods. To this end, we released ground-truth segmentation masks for two frames of each scene in the Mip-NeRF360 dataset
. Limitations:
One current limitation is that non-contiguous objects may, in rare occasions, be assigned the same label. This is mitigated by our regularization and in practice, such objects can trivially be separated. Although our method is class agnostic, we observe a drop in quality for transparent objects, highly-reflective surfaces, or particularly small objects.
Citation
@article{dumery25enforcing,
title = {{Enforcing View-Consistency in Class-Agnostic 3D Segmentation Fields}},
author = {Dumery, Corentin and Fan, Aoxiang and Li, Ren and Talabot, Nicolas and Fua, Pascal},
journal = {{CVPRW}},
year = {2025},
}