MixCount is a large-scale synthetic dataset for mixed-object, open-vocabulary counting, the setting that dominates industrial inspection and sorting, but breaks current counting models. Our automatic generation pipeline produces pixel-perfect labels, text prompts at several levels of detail, and visual exemplars at scale.
58Kcounting scenes
1,522object classes
4M+counting instances
-18.3%MAE on PairTally
-20.14%MAE on FSC-147
Bridging the data gap
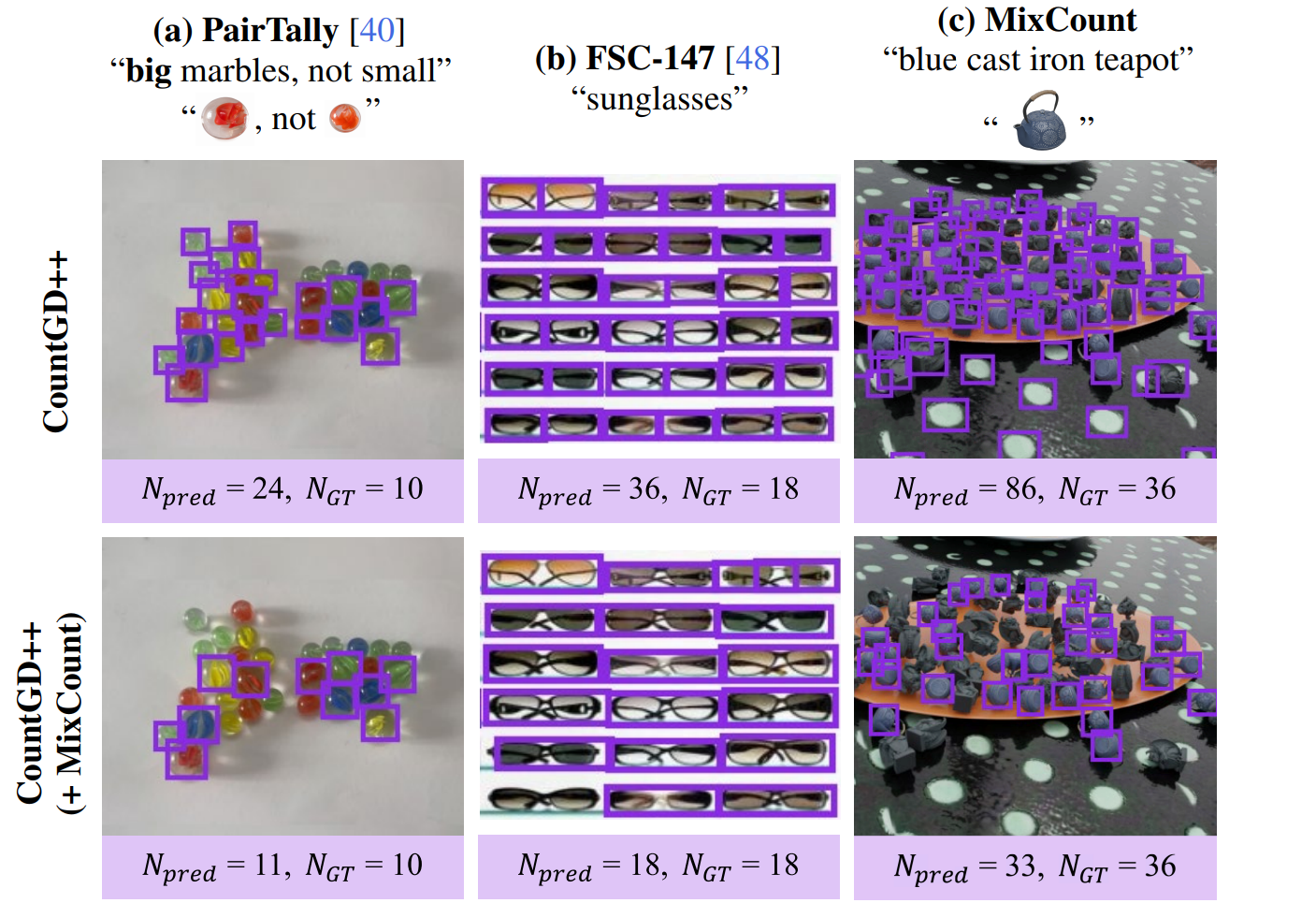
Visual counting models often struggle in mixed-object scenes. Common failure modes include:
(a) Distinguishing visually similar objects, e.g. big marbles in PairTally.
(b) Recognizing self-similar components as a single entity, e.g. counting pairs of sunglasses rather than lenses.
(c) Ignoring repetitive background patterns and focusing on the queried object class.
MixCount combines the scale of synthetic datasets with the photorealism of real-world 3D captures, while targeting these failure modes. As a result, training on MixCount yields about 20% lower error on recent open-vocabulary counting benchmarks.
Dataset
FSC-147
PairTally
MCAC
MixCount
Multiple object types per image
✓
✓
✓
Fine-grained text prompts
✓
✓
External visual exemplars
✓
Segmentation & bounding boxes
✓
✓
# images
6,135
681
20K
58,000
# object classes
147
98
343
1,522
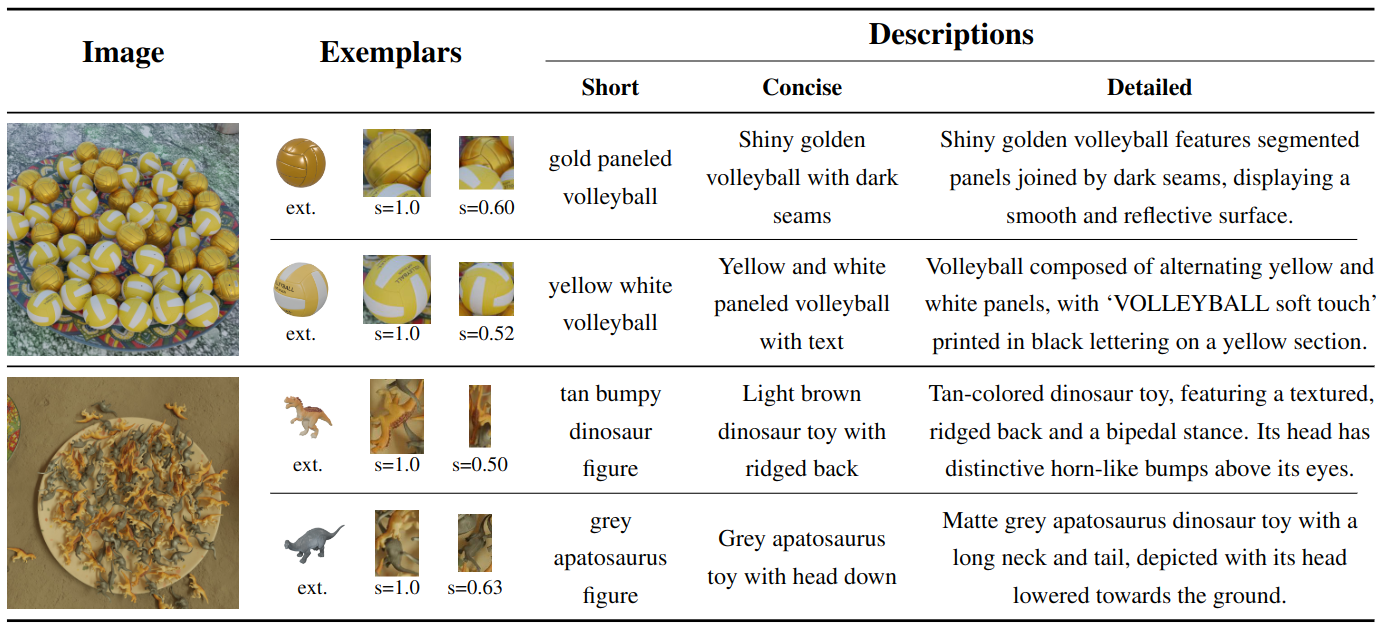
Dataset features: Each sample provides multiple visual exemplars per object (external crops and in-scene crops at different scales) together with short, concise, and detailed text descriptions, enabling flexible open-vocabulary counting prompts.
Annotations: Every image comes with pixel-perfect counting supervision plus dense labels including instance and class segmentations, bounding boxes, depth, and normal maps.
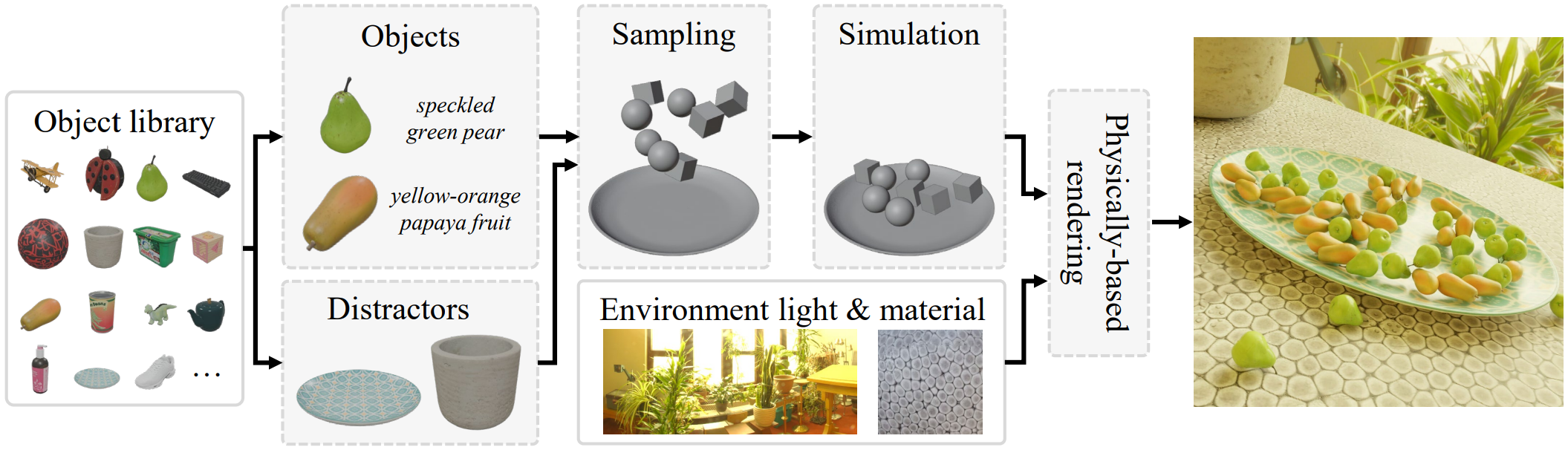
Data generator: Our generator samples objects, distractors, environment, and camera placement to procedurally create photorealistic training samples. All assets are built from high-quality captures of real-world objects, materials, and lighting.
Citation
@article{dumery2026mixcount,
title = {{The MixCount Dataset: Bridging the Data Gap for Open-Vocabulary Object Counting}},
author = {Dumery, Corentin and Amini-Naieni, Niki and Naini, Shervin and Fua, Pascal},
journal = {arXiv preprint arXiv:2605.18063},
year = {2026}
}
Acknowledgements
We thank the following datasets and resources:
DTC,
VasTextures,
LavalIndoor, and
PolyHaven,
as well as the Blender Foundation.
We also thank Andrew Zisserman for insightful discussions. This work is partially funded by the Swiss National Science Foundation, an AWS Studentship, the Reuben Foundation, a Qualcomm Innovation Fellowship (mentors: Dr Farhad Zanjani and Dr Davide Abati), and the AIMS CDT program at the University of Oxford.


 2
2 3
3